- Introduce World-Gymnast, an RL framework that fine-tunes VLA policies inside a learned video world model with VLM-based rewards.
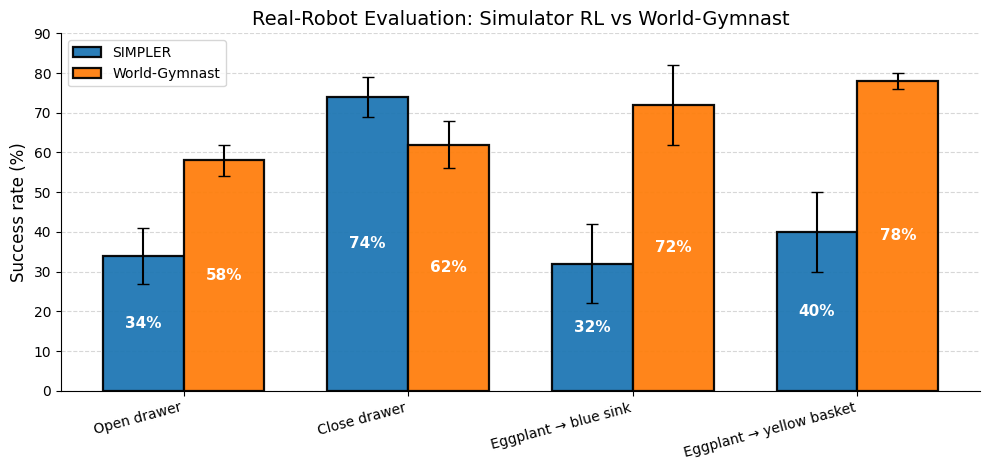
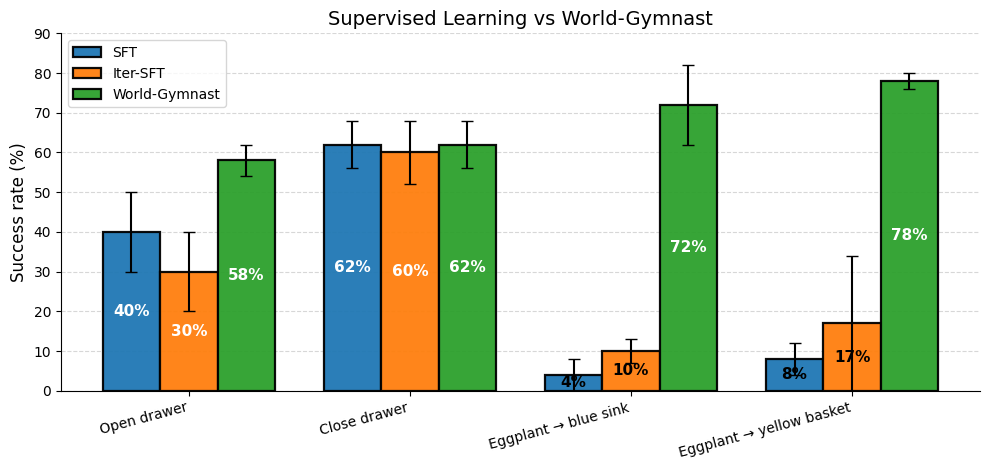
- Demonstrate improved real-robot performance over SFT and simulator-based RL.
- Show that training with distractor augmentation, novel language instructions, and additional tasks improves robustness and success.
- Demonstrate test-time training from a novel frame and iterative world model + policy improvement via a Dyna-style loop.
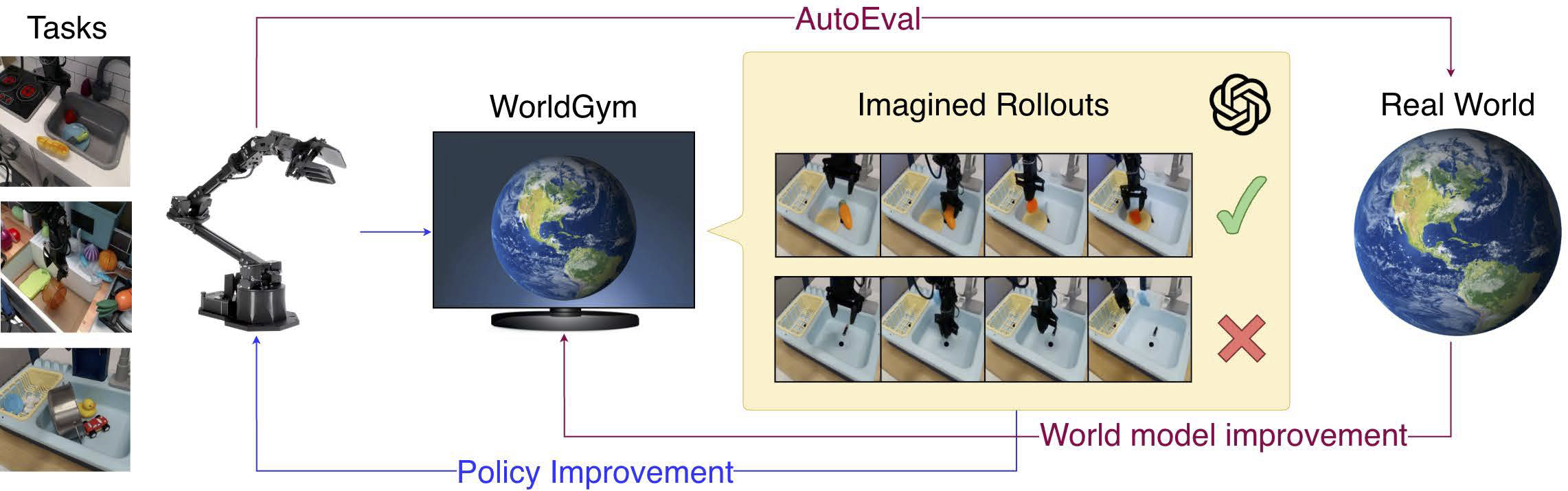
The policy is trained on tasks specified by an initial frame and language instruction. During training, the policy outputs actions which are then passed to the world model which generates imagined rollouts. These rollouts are then passed to a VLM which returns a binary task completion reward. This reward is used to update the policy. Once trained, we evaluate the policy on real robots. The resulting real world rollouts (frame-action sequences) can be further used to improve the world model on the particular environment.